Building a Codenames AI Assistant with Multi-Modal LLMs
Contents
Introduction
Codenames is a word association game where two teams guess secret words based on one-word clues. The game involves a 25-word grid, with each team identifying their words while avoiding the opposing team’s words and the “assassin” word.
I knew that word embeddings could be used to group words based on their semantic similarity. This seemed like a good way to cluster words on the board and generate clues. I was largely successful in getting this to work along with few surprises and learnings along the way.
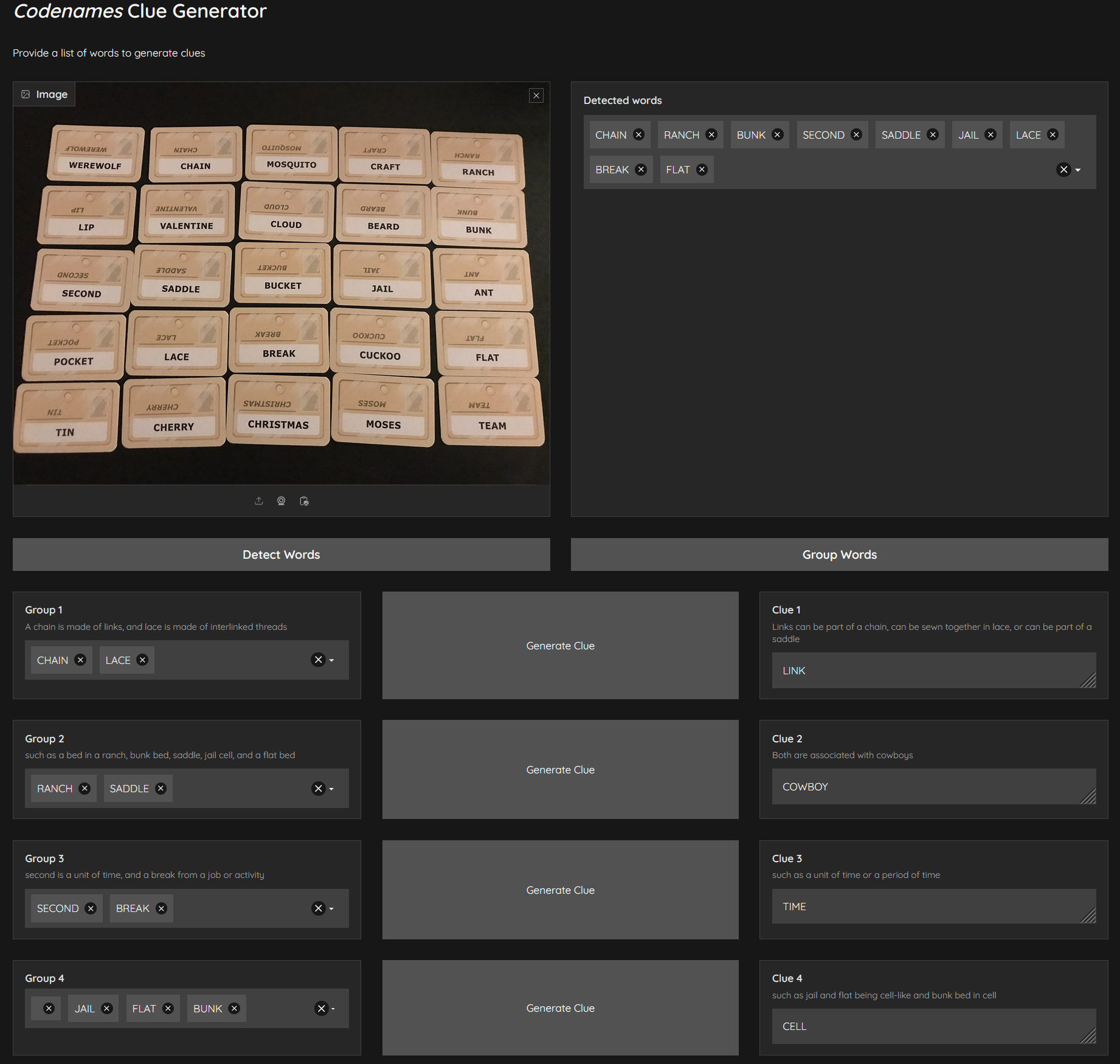
I have published a demo of this Gradio app along with its code in HF Spaces.
Initial attempts
My initial experiments with sentence embedding models did not yield satisfactory results. These models required a more context beyond individual words to deliver precise outcomes. Transitioning to word embedding models proved to be more effective; however, I still encountered challenges in filtering out undesired outputs such as foreign language terms and compound words. Additionally, employing similarity search techniques like kNN and Cosine similarity did not yield optimal results.
I switched to word embedding models, which were better, but I still had to filter out unwanted outputs like foreign language words and compound words. Similarity search methods like kNN and Cosine similarity also didn’t give me the best results.
Extracting the game words using OpenCV also turned out to be more involved than I expected. I had to deal with shadows, uneven exposure, grid detection, and draw bounding boxes. The upside-down clue words also caused problems for the character recognition model.
Multi-Modal LLM Solution
This is when I decided to try a small local Large Language Model (LLM) for this. I used microsoft/Phi-3-Mini-4K-Instruct which is a 3.8B parameters, lightweight LLM by Microsoft. Surprisingly this model consistently produced high-quality results with minimal effort. I split the task into 3 sections:
- Identifying words in the game using OCR
- Grouping of words
- Generating clues for each groups
OCR for text extraction
The Phi-3 model family also has a multimodal version called microsoft/Phi-3-vision-128k-instruct with a focus on very high-quality, reasoning dense data both on text and vision. I used this model for OCR. It worked like a charm, eliminating the need for complex image processing techniques. Unfortunately the structured output generation library I used (Outlines, explained later) doesn’t yet support Vision models so I couldn’t use this as a single model for both OCR and text generation. So I leveraged Nvidia hosted LLM service (NIM) to perform the OCR task.
| |
Grouping of words
I employed few-shot prompting technique along with a custom system prompt to cluster words that share common characteristics. I observed that when we instruct the Language Model (LLM) to group words, the resulting clusters are often random, regardless of the initial instructions. However, prompting the LLM to group words and then explain the rationale behind the grouping led to more coherent and meaningful word groupings.
| |
Generation of Clues
I split the clue generation logic separately even though LLMs could generate them at the time of grouping the words together. This is because I wanted to be able to regenerate better clues for individual groups without having to regroup the entire word list every time.
| |
Outlines
One reason why I tried other options before LLMs because LLMs generations are stochastic and I needed parsable output for my web page i.e, I need guarantee that the output text will have a certain format. That’s when I came across the Outlines library which is one among the many popular guided generations libraries. It helped me generate structured text consistently, making it easy to integrate with my app’s interface.
The basic idea of Outlines is simple: in each state, it gets a list of symbols that correspond to completions that partially match the regular expression. It masks the other symbols in the logits returned by a large language model, so we derive a new FSM whose alphabet is the model’s vocabulary. We can do this in only one pass over the vocabulary.
| |
Reflections and the Road Ahead
Initially, I underestimated the LLM approach, considering it excessive for what seemed like a straightforward issue. However, I was mistaken. Leveraging LLM significantly expedited the generation of usable outcomes, saving considerable time. Over time, despite its substantial size and computational demands, this ease of use aspect will boost its acceptance. As momentum builds, further research and optimization will ensue, resulting in more compact, effective, and intelligent models. Although optimized algorithms and specialized models will retain significance in particular domains, LLMs are positioned to transform numerous sectors with their adaptability and potency.
Author tmzh
LastMod 2024-06-20