While chatbots have grown common in applications like customer service, they have several shortcomings which disrupts user experience. Traditional chatbots rely on pattern matching and database lookups, which are ineffective when a user’s question deviates from what was expected. Responses may feel impersonal and fail to address the true intent when questions deviate slightly from pattern matching rules.
This is where large language models (LLMs) can provide value. LLMs are better equipped to handle out-of-scope questions due to their ability to understand context and previous exchanges. They can generate more personalized responses compared to typical rule-based chatbots. As such, chatbots represent a prime use case for generative AI in enterprises.
When considering Generative AI use cases in an Enterprise context, it is hard to look past Chatbots utilizing Large Language Models (LLMs). Traditional chatbots can feel impersonal and inadequate due to their reliance on pattern matching and limited context understanding. In contrast, interacting with LLMs can feel natural since due to their improved understanding of context and personalized responses. This chatbot an ideal use case to explore Generate AI in enterprises.
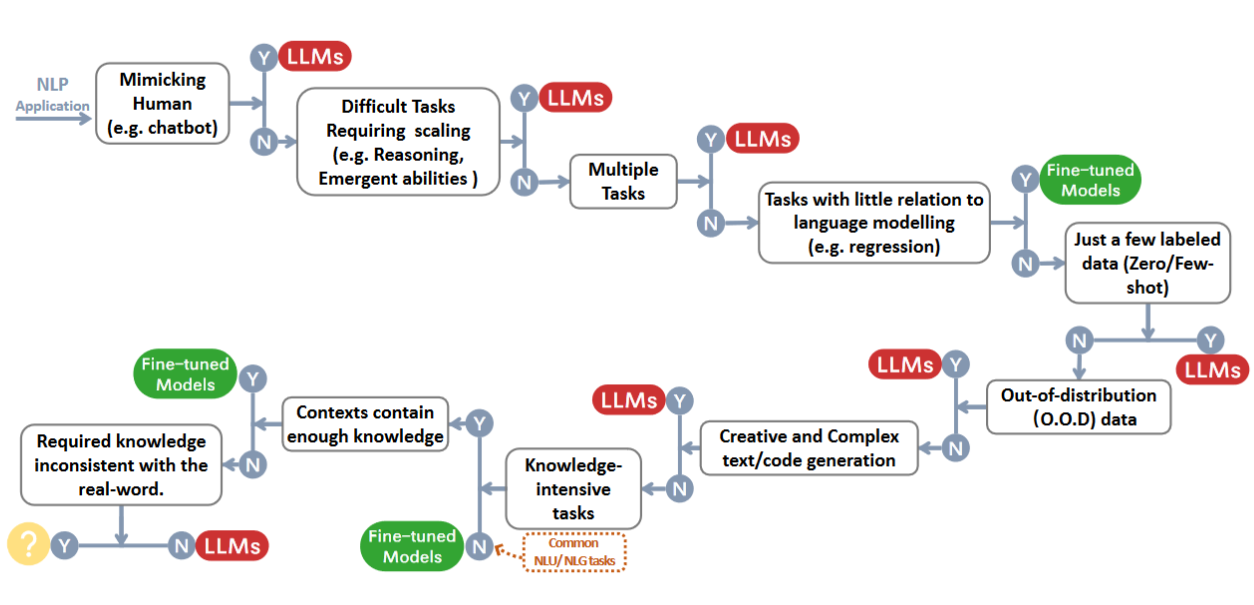 Source: Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond (arXiv:2304.13712)
Source: Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond (arXiv:2304.13712)
To help an LLM answer based on internal knowledge base, one approach utilizes prompting i.e., inserting knowledge corpora into the prompt along with user queries.
However, using LLMs in this manner can lead to responses that lack constraints, resulting in potential factual inaccuracies and irrelevance, especially when dealing with topics beyond the scope of the training data. This phenomenon is referred to as “hallucination.”
To address this, knowledge retrieval can be incorporated to ground the LLM’s responses in factual information from curated sources. This is known as Retrieval Augmented Generation
How Retrieval Augmented Generation works
Retrieval augmented generation (RAG) combines two main components: a retrieval model and a generation model.
The retrieval model searches external knowledge bases to extract facts relevant to a user’s query. It represents words and documents as embeddings, calculating similarity between query and document embeddings to retrieve top results.
The generation model—typically a large language model—accepts the retrieved information as input. It produces natural language responses guided by this context without direct access to the raw knowledge base. This anchoring to concrete facts mitigates generation of incorrect statements compared to relying solely on the LLM.
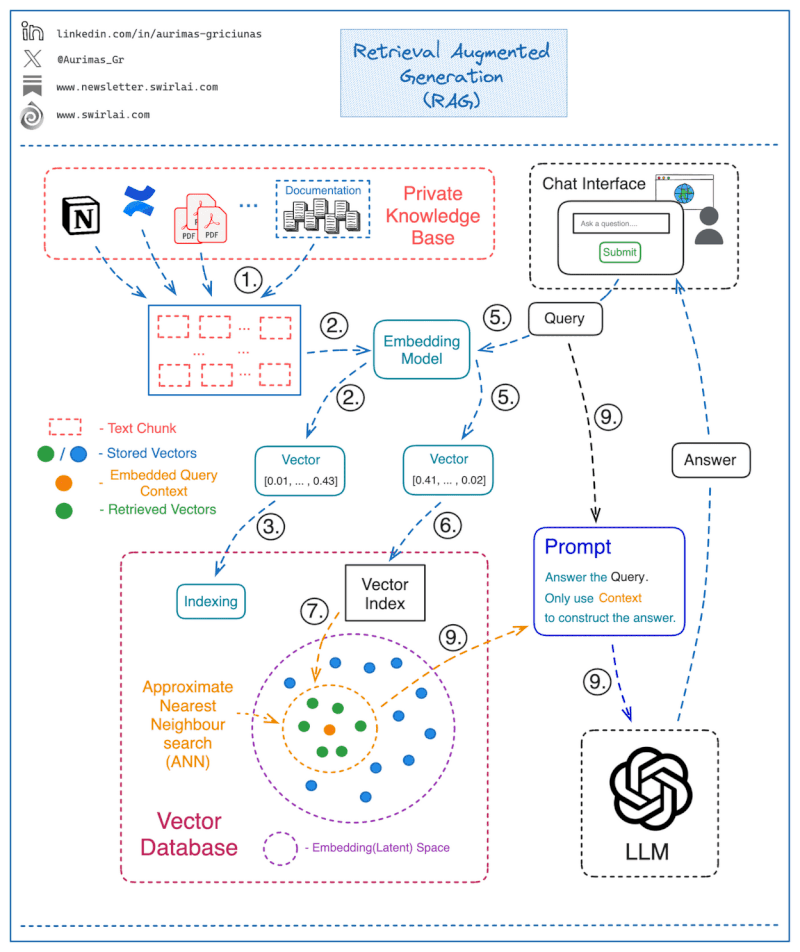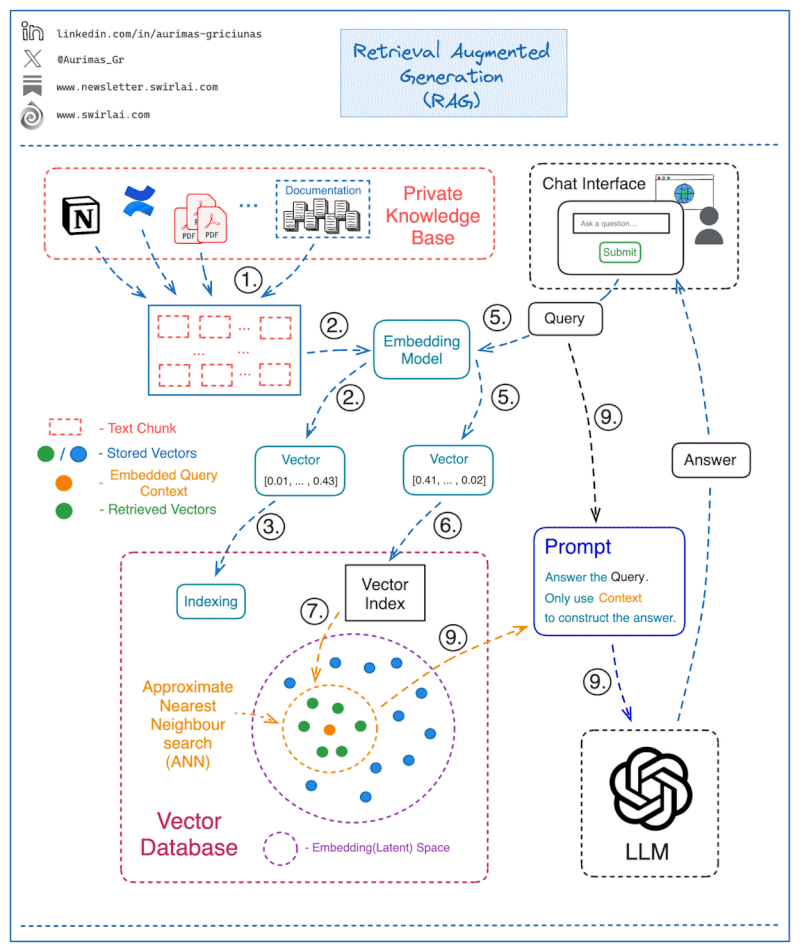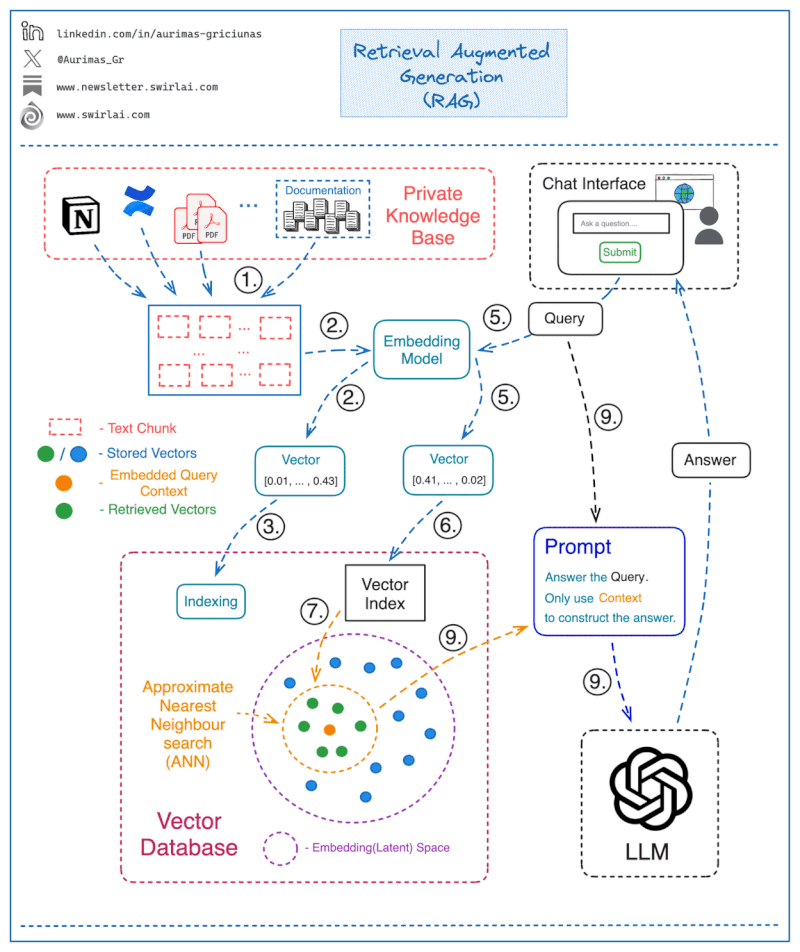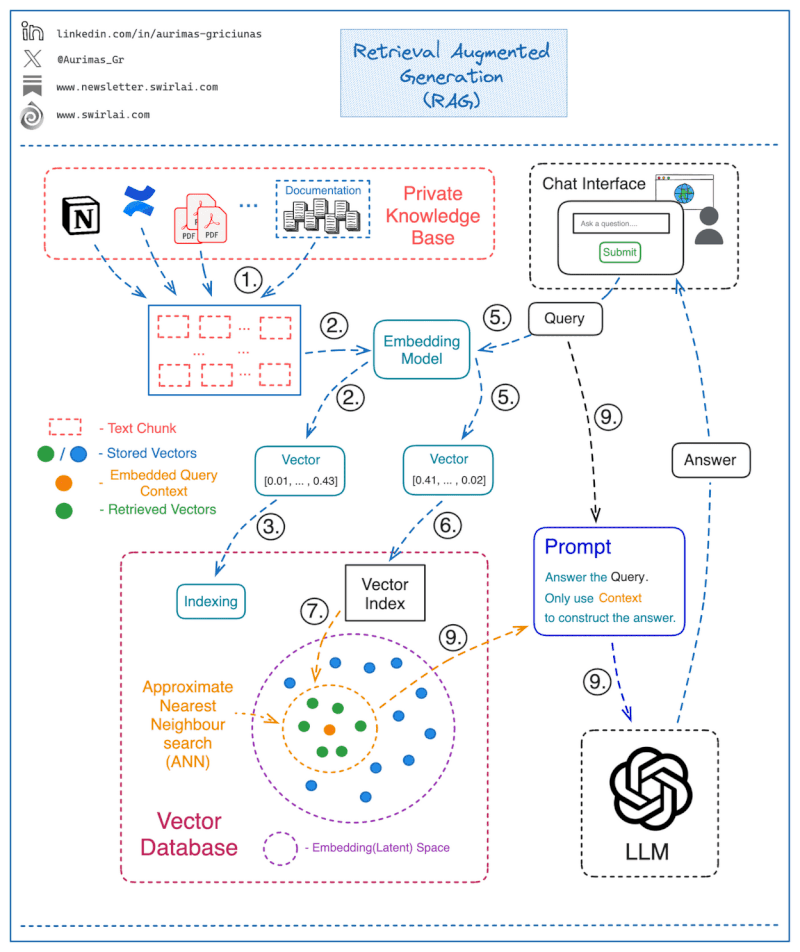 Source: LLM based chatbots to query your private knowledge base
Source: LLM based chatbots to query your private knowledge base
Advantages of RAG
RAG offers several advantages over both LLM-based question answering (QA) systems and traditional rule-based chatbots.
Compared to LLM QA, RAG can provide answers based on externally retrieved facts without the need for expensive fine-tuning. It also offers traceability to the cited information sources.
In contrast to traditional chatbots, RAG excels in handling ambiguous and out-of-scope queries through its contextual understanding. It goes beyond simple rule-based responses and generates more human-like and personalized answers, improving the user experience.
The hybrid approach also has computational benefits as well. By employing lighter models specifically designed for retrieval tasks that prioritize semantic similarity over language modeling, RAG enables quicker retrievals. This efficiency is achieved by operating in a lower dimensional space compared to LLM, resulting in faster response times.
Overall, RAG leverages the strengths of both retrieval and language models. By anchoring flexible conversational abilities to verifiable facts, it offers a more robust framework for open-domain dialogue than previous paradigms alone.
Implementation
In this blog post, we will develop a retrieval augmented generation (RAG) based LLM application from scratch. We will be building a chatbot that answers questions based on a knowledge base. For the knowledge base, we will use E-commerce FAQ dataset.
Setup
Load documents
The chat dataset used for this project, is in a JSON format as an array of key-value pairs. We will split it into chunks of n characters but to retain the information within each chunk, we will ensure that each QnA pair is loaded as an individual chunk.
import json
from pathlib import Path
import uuid
file_path='./data/faq_dataset.json'
data = json.loads(Path(file_path).read_text())
documents = [json.dumps(q) for q in data['questions']] # encode QnA as json strings for generating embeddings
metadatas = data['questions'] # retain QnA as dict in metadata
ids = [str(uuid.uuid1()) for _ in documents] # unique identifier for the vectors
Prepare embeddings
Next we will use an embedding model to generate vector representations of the chunks. Here we are using BAAI/bge-small-en-v1.5 model. This is a tiny model, less than 150 MB in size and uses 384 dimensions to store semantic information, but it is sufficient for retrieval. Since embedding model needs to process a lot more tokens than answering model which only needs to process the prompt, it is better to keep it lightweight. If we have enough memory, we can use a larger model to generate embeddings.
import chromadb
from chromadb.utils import embedding_functions
client = chromadb.Client()
emb_fn = embedding_functions.SentenceTransformerEmbeddingFunction(model_name="BAAI/bge-small-en-v1.5")
collection = client.create_collection(
name="retrieval_qa",
embedding_function=emb_fn,
metadata={"hnsw:space": "cosine"} # l2 is the default
)
Since our FAQ dataset is very small, and we have a light embedding model, it is quite inexpensive to calculate the embeddings. So we will use in-memory non-persistent Chroma client as a Vector store. Vector stores is a data structure or database that specialize in storing and retrieving embeddings. They also provide methods for performing similarity search and Nearest neighbour search. Note that in ChromaDB, the default index type is Hierarchical Navigable Small Worlds (hnsw) and distance function is l2. However other distance functions are also available:
| Distance | Parameter | Equation |
|---|---|---|
| Squared L2 | l2 | \(d = \sum\left(A_i-B_i\right)^2\) |
| Inner product | ip | \(d = 1.0 - \sum\left(A_i \times B_i\right)\) |
| Cosine Similarity | cosine | \[d = 1.0 - \frac{\sum\left(A_i \times B_i\right)}{\sqrt{\sum\left(A_i^2\right)} \cdot \sqrt{\sum\left(B_i^2\right)}}\] |
For more expensive embedding operations involving larger dataset or embedding models, we can use a persistent store such as the one offered by ChromaDB itself or other options such as pgVector, Pinecone, or Weaviate
Retrieval
Query Index
We can now retrieve a set of documents closest to the query:
query = "How can I open an account?"
docs = collection.query(query_texts=[query],
n_results=3)
{'ids': [['d9b8bc80-7093-11ee-a189-00155d07b3f4',
'd9b8bee2-7093-11ee-a189-00155d07b3f4',
'd9b8bece-7093-11ee-a189-00155d07b3f4']],
'embeddings': None,
'documents': [['{"question": "How can I create an account?", "answer": "To create an account, click on the \'Sign Up\' button on the top right corner of our website and follow the instructions to complete the registration process."}',
'{"question": "Can I order without creating an account?", "answer": "Yes, you can place an order as a guest without creating an account. However, creating an account offers benefits such as order tracking and easier future purchases."}',
'{"question": "Do you have a loyalty program?", "answer": "Yes, we have a loyalty program where you can earn points for every purchase. These points can be redeemed for discounts on future orders. Please visit our website to learn more and join the program."}']],
'metadatas': [[{'question': 'How can I create an account?',
'answer': "To create an account, click on the 'Sign Up' button on the top right corner of our website and follow the instructions to complete the registration process."},
{'question': 'Can I order without creating an account?',
'answer': 'Yes, you can place an order as a guest without creating an account. However, creating an account offers benefits such as order tracking and easier future purchases.'},
{'question': 'Do you have a loyalty program?',
'answer': 'Yes, we have a loyalty program where you can earn points for every purchase. These points can be redeemed for discounts on future orders. Please visit our website to learn more and join the program.'}]],
'distances': [[0.19405025243759155, 0.3536655902862549, 0.3666747808456421]]}
For simple and straightforward user queries, it may be sufficient to return the top match. But consider a question like below:
query = "What are the conditions for requesting a refund? Do I need to keep the receipt?"
docs = collection.query(query_texts=[query],
n_results=3)
The top 3 responses are:
[[{'question': "Can I return a product without a receipt?",
'answer': "A receipt or proof of purchase is usually required for returns. Please refer to our return policy or contact our customer support team for assistance."},
{'question': "Can I return a product if I no longer have the original receipt?",
'answer': "While a receipt is preferred for returns, we may be able to assist you without it. Please contact our customer support team for further guidance."},
{'question': "What is your return policy?",
'answer': "Our return policy allows you to return products within 30 days of purchase for a full refund, provided they are in their original condition and packaging. Please refer to our Returns page for detailed instructions."}
]]
Clearly just returning the answer for the closest matched question will be incomplete and unsatisfactory for the user. The ideal answer needs to incorporate all facts from the relevant document chunks. This is where a generation model can help.
Generation
Load a generative model
LLMs are often trained and released as unaligned base models initially which simply take in text and predict the next token. Bloom, Llama2 and Mistral are examples of such base models. But for practical use, we often require models that are further fine-tuned for the task. For RAG and generally speaking for chat agents we need Instruct models that are further fine-tuned on instruction-response pairs.
For this demonstration, I used an instruction fine-tuned model Mistral-7B-Instruct-v0.1 from Mistral. The Mistral model is in particular impressive for the quality of its text generation given the relatively small model size (7B). This leads to quite performant prompt evaluation and response generation. I used the GPTQ quantized version which further reduces the model size and improves the prompt evaluation and token generation throughput significantly.
GPTQ models are quantized versions that reduces memory requirements with a slight tradeoff of intelligence. Hugging Face transformers supports loading of GPTQ models since version
4.32.0using AutoGPTQ library. You can learn more about this here
import torch
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
models = {
"wizardLM-7B-HF" : "TheBloke/wizardLM-7B-HF",
"wizard-vicuna-13B-GPTQ" : "TheBloke/wizard-vicuna-13B-GPTQ",
"WizardLM-13B" : "TheBloke/WizardLM-13B-V1.0-Uncensored-GPTQ",
"Llama-2-7B" : "TheBloke/Llama-2-7b-Chat-GPTQ",
"Vicuna-13B" : "TheBloke/vicuna-13B-v1.5-GPTQ",
"WizardLM-13B-V1.2" : "TheBloke/WizardLM-13B-V1.2-GPTQ",
"Mistral-7B" : "TheBloke/Mistral-7B-Instruct-v0.1-GPTQ"
}
model_name = "Mistral-7B"
tokenizer = AutoTokenizer.from_pretrained(models[model_name])
model = AutoModelForCausalLM.from_pretrained(models[model_name],
torch_dtype=torch.float16,
device_map="auto")
Alternatively, you can use any of the other instruct models. I have had good results with WizardLM-13B as well. Note that the models we choose must fit the VRAM of your GPU. Often you can find the memory requirements of a model in their HuggingFace model card such as here.
Build a prompt
Every instruct model works best when we provide it with prompts as per a specific template on which it was trained. Since this template can vary between models, to reliably apply model-specific chat template, we can use the Transformers chat template, which allows us to format a list of messages as per the model-specific chat template.
chat = [
{"role": "user", "content": "Hello, how are you?"},
{"role": "assistant", "content": "I'm doing great. How can I help you today?"},
{"role": "user", "content": "I'd like to show off how chat templating works!"},
]
tokenizer.use_default_system_prompt = True
tokenizer.apply_chat_template(chat, tokenize=False)
<s>[INST] <<SYS>>
You are a helpful, respectful and honest support executive. Always answer as helpfully as possible, while being safe. While answering, use the information provided in the earlier conversations only. If the information is not present in the prior conversation, or If you don't know the answer to a question, please don't share false information. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct.
<</SYS>>
Hello, how are you? [/INST] I'm doing great. How can I help you today? </s><s>[INST] I'd like to show off how chat templating works! [/INST]
In our case, we want to customize the system prompt to pass the retrieved document chunks as a context for QnA.
This is done by disabling the default system prompt and configuring the tokenizer to use default_chat_template. This allows us to override the message for the system role.
chat = []
system_message = "You are a helpful, respectful and honest support executive. Always be as helpful as possible, while being correct. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. Use the following piece of context to answer the questions. If the information is not present in the provided context, answer that you don't know. Please don't share false information."
for d in docs['metadatas'][0]:
# append context to system message
system_message += f"\n Question: {d['question']} \n Answer: {d['answer']}"
chat.append({"role": "system", "content": system_message})
chat.append({"role": "user", "content": query})
prompt = tokenizer.apply_chat_template(chat, tokenize=False)
This will insert a set of relevant questions and answers as additional context within the prompt so that the model can use this information to give an answer. For our example the constructed prompt looks like this:
<s>[INST] <<SYS>>
You are a helpful, respectful and honest support executive. Always be as helpful as possible, while being correct. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. Use the following piece of context to answer the questions. If the information is not present in the provided context, answer that you don't know. Please don't share false information.
Question: How can I create an account?
Answer: To create an account, click on the 'Sign Up' button on the top right corner of our website and follow the instructions to complete the registration process.
Question: Can I order without creating an account?
Answer: Yes, you can place an order as a guest without creating an account. However, creating an account offers benefits such as order tracking and easier future purchases.
Question: Do you have a loyalty program?
Answer: Yes, we have a loyalty program where you can earn points for every purchase. These points can be redeemed for discounts on future orders. Please visit our website to learn more and join the program.
<</SYS>>
How can I open an account? [/INST]
Generate response
Now we have everything needed to generate a user-friendly response from LLM.
encodeds = tokenizer.apply_chat_template(chat, return_tensors="pt")
model_inputs = encodeds.to(model.device)
model.to(model.device)
generated_ids = model.generate(model_inputs, max_new_tokens=100, do_sample=True)
answer = tokenizer.batch_decode(generated_ids[:, model_inputs.shape[1]:])[0]
<s>[INST] <<SYS>>
You are a helpful, respectful and honest support executive. Always be as helpful as possible, while being correct. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. Use the following piece of context to answer the questions. If the information is not present in the provided context, answer that you don't know. Please don't share false information.
Question: How can I create an account?
Answer: To create an account, click on the 'Sign Up' button on the top right corner of our website and follow the instructions to complete the registration process.
Question: Can I order without creating an account?
Answer: Yes, you can place an order as a guest without creating an account. However, creating an account offers benefits such as order tracking and easier future purchases.
Question: Do you have a loyalty program?
Answer: Yes, we have a loyalty program where you can earn points for every purchase. These points can be redeemed for discounts on future orders. Please visit our website to learn more and join the program.
<</SYS>>
How can I open an account? [/INST] To open an account, click on the 'Sign Up' button on the top right corner of our website and follow the instructions to complete the registration process.</s>
Everything after the last token [/INST] is the response we seek. Keep in mind that, from an LLM perspective generating responses is merely continuing the text prompt that we passed to it. To retrieve the generated response we need to index from the input prompt length.
answer = tokenizer.batch_decode(generated_ids[:, model_inputs.shape[1]:])[0]
Build a Chat UI
Now we have all the necessary ingredients to build a chatbot. Gradio library offers several ready-made components that simplify the process of building a Chat UI. We need to wrap our token generation process as below:
import gradio as gr
with gr.Blocks() as chatbot:
with gr.Row():
answer_block = gr.Textbox(label="Answers", lines=2)
question = gr.Textbox(label="Question")
generate = gr.Button(value="Ask")
generate.click(respond, inputs=question, outputs=[answer_block, global_state, exampleso])
chatbot.launch()
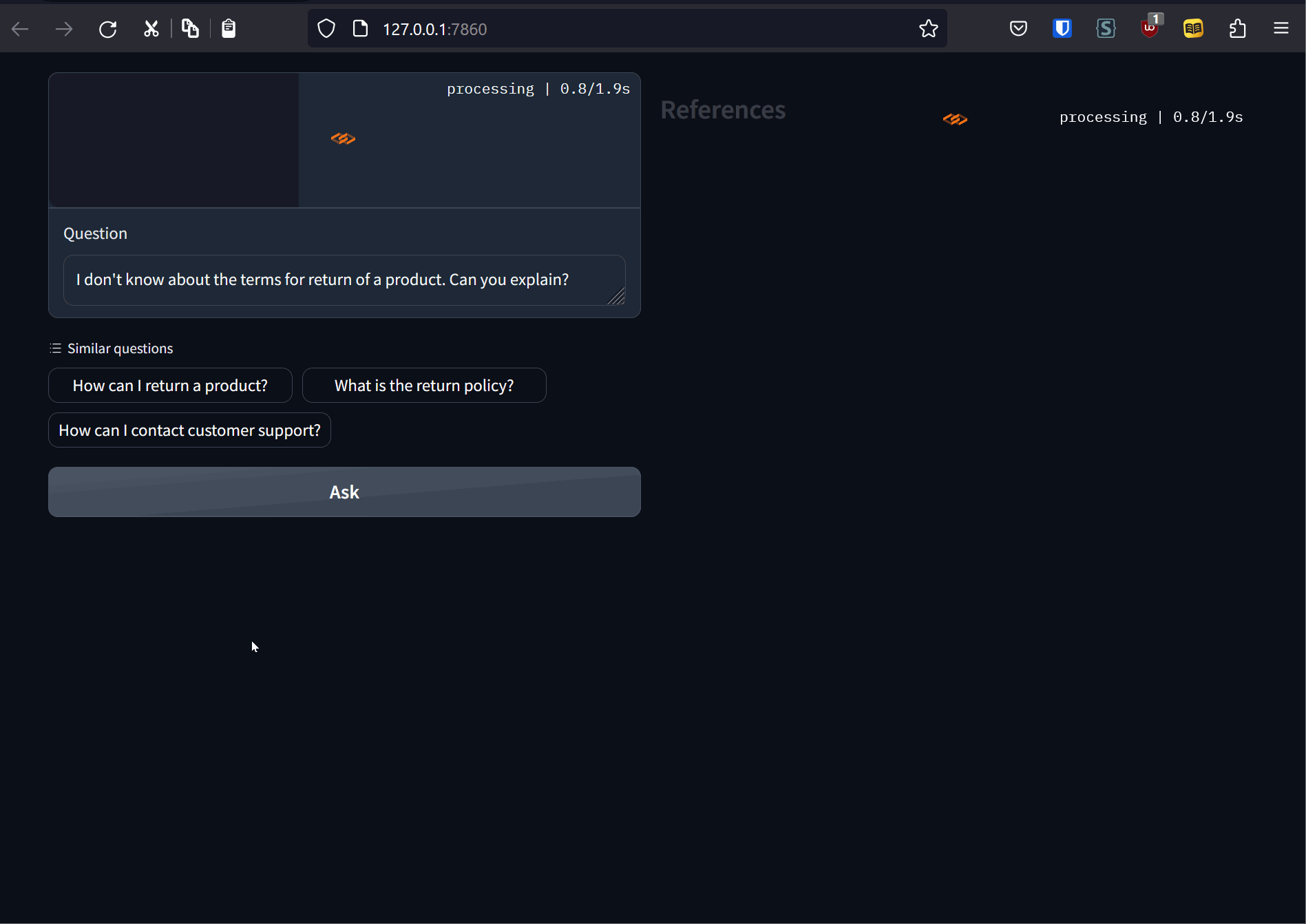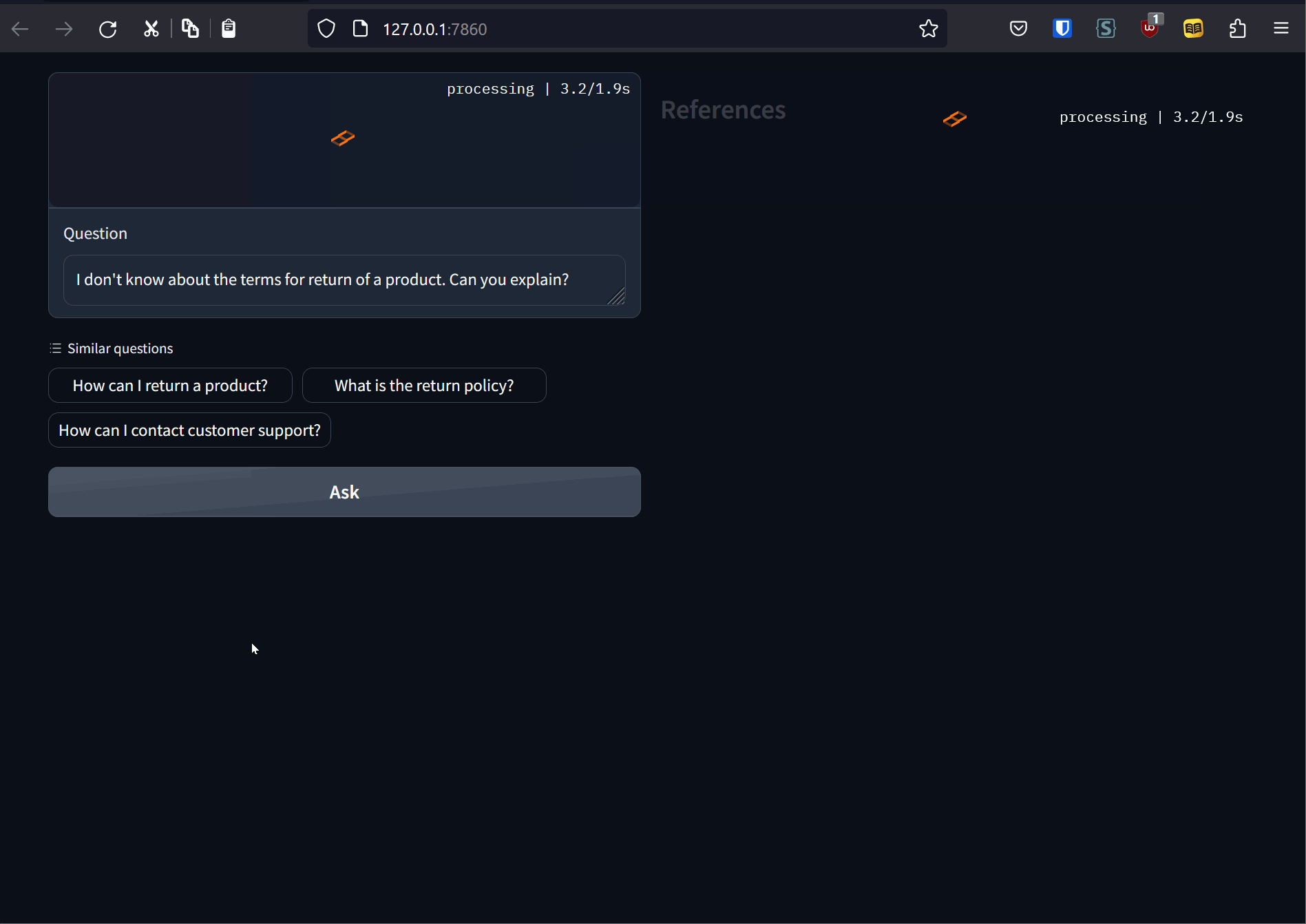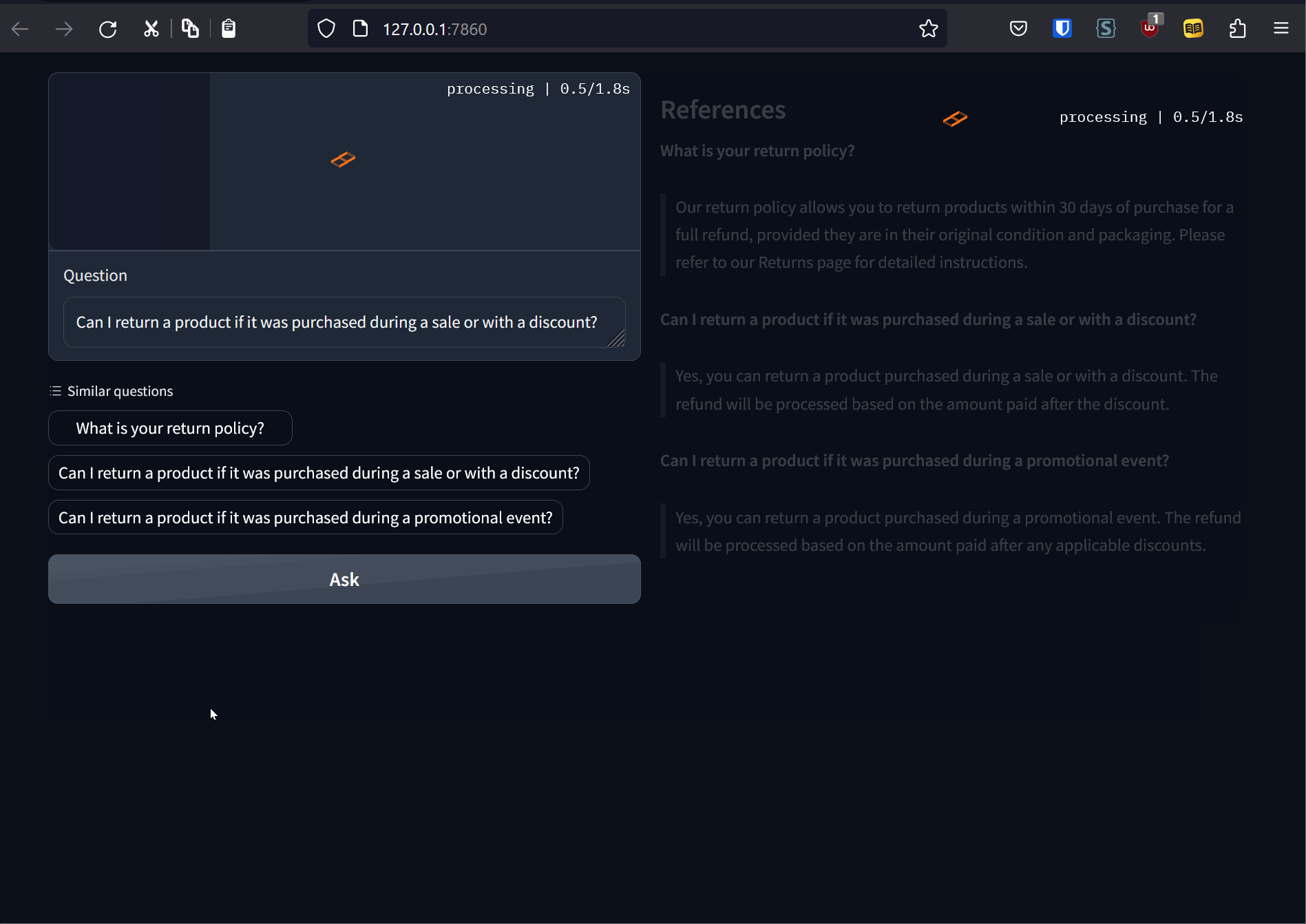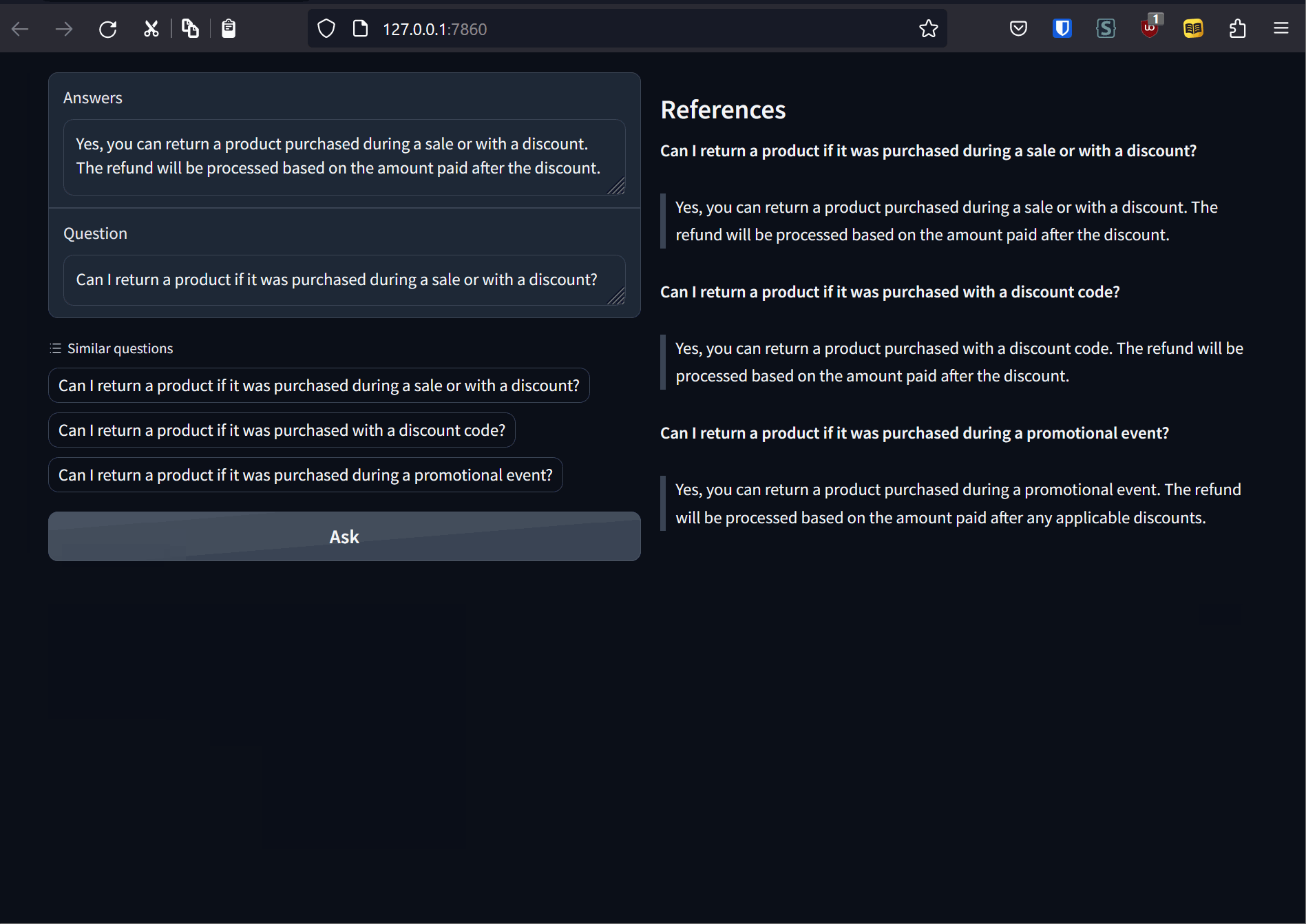
Along with generating a response, we can also give a list of references to let the user know the source of truth for responses. We can also suggest other relevant questions that the users can click to follow. With these additions, the code for the chat component is as follows:
import gradio as gr
import random
samples = [
["How can I return a product?"],
["What is the return policy?"],
["How can I contact customer support?"],
]
def update_examples():
global samples
samples = get_new_examples()
return gr.Dataset.update(samples=samples)
def respond(query):
global samples
docs = collection.query(query_texts=[query], n_results=3)
chat = []
related_questions = []
references = "## References\n"
system_message = "You are a helpful, respectful and honest support executive. Always be as helpful as possible, while being correct. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. Use the following piece of context to answer the questions. If the information is not present in the provided context, answer that you don't know. Please don't share false information."
for d in docs['metadatas'][0]:
# prepare chat template
system_message += f"\n Question: {d['question']} \n Answer: {d['answer']}"
# Update references
references += f"**{d['question']}**\n\n"
references += f"> {d['answer']}\n\n"
# Update related questions
related_questions.append([d['question']])
chat.append({"role": "system", "content": system_message})
chat.append({"role": "user", "content": query})
encodeds = tokenizer.apply_chat_template(chat, return_tensors="pt")
model_inputs = encodeds.to(model.device)
streamer = TextStreamer(tokenizer)
model.to(model.device)
generated_ids = model.generate(model_inputs, streamer=streamer, temperature=0.01, max_new_tokens=100, do_sample=True)
answer = tokenizer.batch_decode(generated_ids[:, model_inputs.shape[1]:])[0]
answer = answer.replace('</s>', '')
samples = related_questions
related = gr.Dataset.update(samples=related_questions)
yield [answer, references, related]
def load_example(example_id):
global samples
return samples[example_id][0]
with gr.Blocks() as chatbot:
with gr.Row():
with gr.Column():
answer_block = gr.Textbox(label="Answers", lines=2)
question = gr.Textbox(label="Question")
examples = gr.Dataset(samples=samples, components=[question], label="Similar questions", type="index")
generate = gr.Button(value="Ask")
with gr.Column():
references_block = gr.Markdown("## References\n", label="global variable")
examples.click(load_example, inputs=[examples], outputs=[question])
generate.click(respond, inputs=question, outputs=[answer_block, references_block, examples])
chatbot.queue()
chatbot.launch()
Conclusion
With the above setup, we can build a chatbot that can provide truthful responses based on an organization’s knowledge base. Since the model possesses the language understanding typical of all LLMs, it is able to respond to questions phrased in different manners. And since the responses are tailored to follow a question-and-answer format, the user experience is not disruptive and they don’t feel like talking to an impersonal bot.