Last year OpenAI released the Generative Pre-trained Transformer 2 (GPT-2) model. GPT-2 was a language model with 1.5 billion parameters, trained on 8 million web pages. It generated quite a buzz as it could generate coherent text, comprehend paragraphs, answer questions, and summarize text and do all sorts of smart stuff… all without any task-specific learning. OpenAI even deemed the model too dangerous to release but eventually ended up releasing them.
In May 2020, OpenAI released their follow-up GPT-3 model which took the game several notches higher. They trained it with 175 billion parameters, using close to half-a-trillion tokens. The model and its weights alone would take up 300GB VRAM. This is a drastic increase in scale and complexity, anyway you look at it. So what can a huge model like this achieve and why has it reinvigorated the talks ?
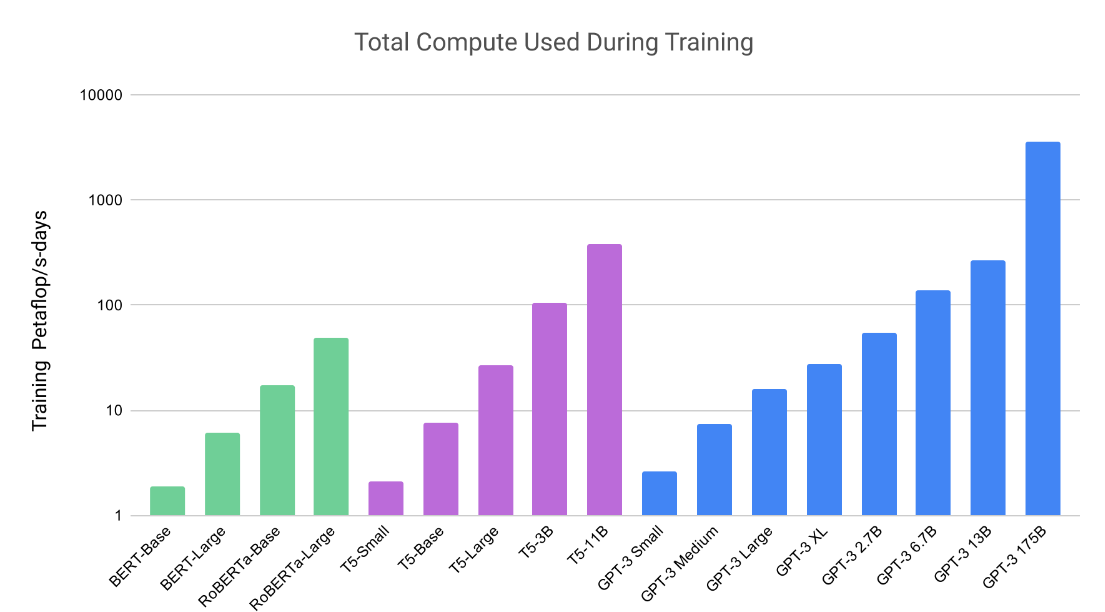
GPT-3 can write poetry, mimic the writing style of personalities. It also performs better than an average college applicant in SAT analogy problems, generates cohesive stories, writes news articles that are hard to distinguish from a human-written article. You can even ask it to do system admin jobs in natural language and it will come up with shell commands and execute them- like a seasoned sysadmin.
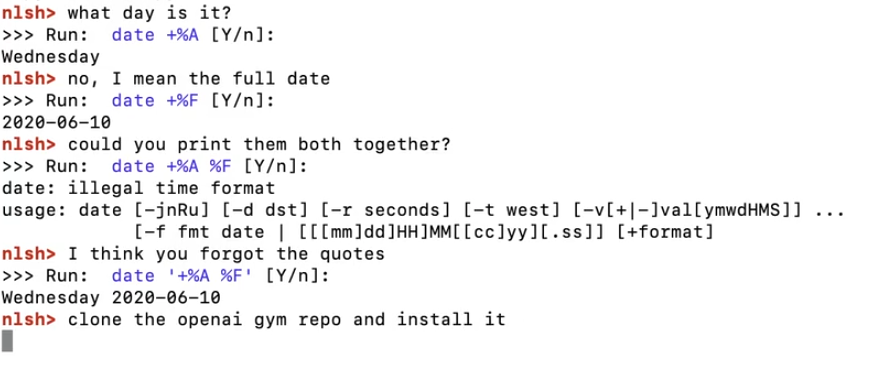
Learning how to learn
One of the amazing aspects of the GPT-3 model is that it doesn’t need any task-specific fine-tuning and yet achieves decent results on many of the Natural Language Processing (NLP) benchmarks and tasks. OpenAI’s claim is that if an NLP model is sufficiently complex and if it has been trained on a large volume of data, it can learn to do new tasks only by looking at few examples prompts i.e, the model has learned the ability to learn new tasks on the go. They call it “Few Shot Learning”. You can see that in action in the chart below.
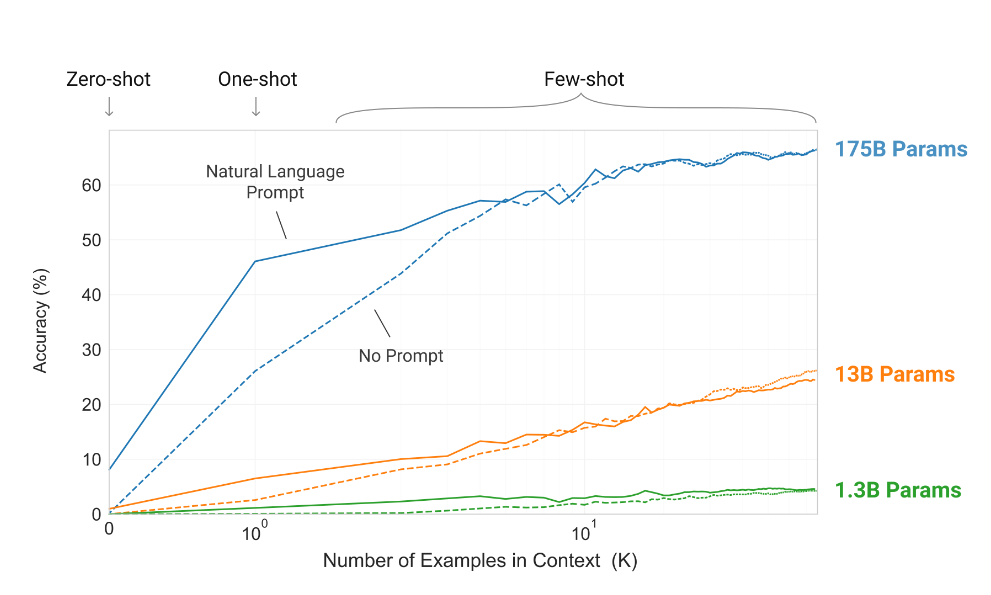
In the above chart, you can see when the GPT-3 175B model is given with few examples, the accuracy rate shoots up compared to a poor learner (1.3B or even the 13B parameter model). The ability to learn is one of the defining characteristics of Artificial General Intelligence (AGI) and now you can understand why GPT-3 is generating the buzz.
Is Language enough to model reality?
GPT-3 has no direct exposure to reality, except via a large corpus of text. Yet the knowledge imparted from this large volume of text allows GPT-3 to reason (arguably) about the physical world as seen in the example below

In fact, GPT-3 also demonstrates surprising ability outside the traditional NLP domain. It can do certain non-linguistic tasks like simple arithmetics. This begs the question, whether modeling language alone is sufficient to form an understanding of reality? We use language to describe our world. So a relation between words should correspond to a relation between the real world entities represented by those words. Some reason that ML models are transitive (i.e, if X models Y and Y models Z, then X models Z) and since language itself is an approximate model of the world, a language model should be an approximate representation of the world.
The upper-bound of the effectiveness of scale
Another surprising outcome of GPT-3 is that the performance has not tapered as the model got more complex. When GPT-2 got released most people speculated that we will soon hit the upper bound on the returns from further scaling up the model. But that hasn’t happened with GPT-3. With a more complex model, GPT-3 has shown big improvements in its performance and seems to get better at learning new tasks (see the widening gap between zero-shot and few-shot benchmarks).
As recently as last year, training a model with 175B seemed far off into the future. The Human brain is estimated to contain around 100 trillion neurons, how long before we reach that figure and what would AI look like as it approaches the figure?
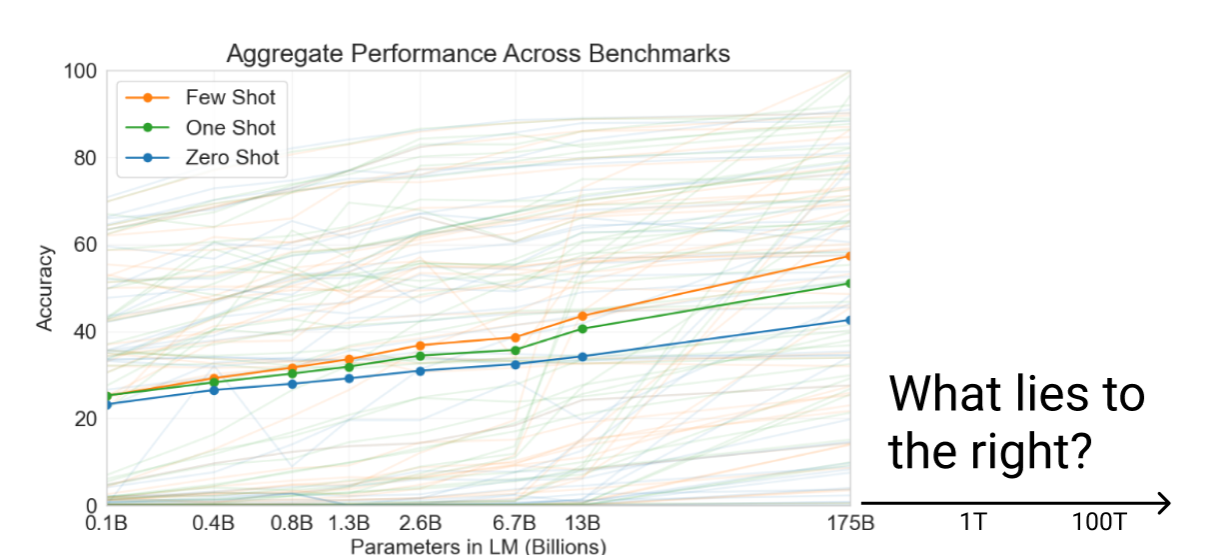
Now I agree that I am playing to the gallery here and being sensational. Biological neurons and ML neurons are quite different. A CNN model can do object detection (in fact better than us) but it doesn’t share the same structure with our visual cortex. This is why CNN outperforms humans in certain tasks like detecting anomalies in medical images, yet they can get confused between a ball and a referee’s head.
Not everyone buys the scaling hypothesis. Detractors like Marcus claim that just because we know how to stack ladders doesn’t mean that we can build ladders to the moon. The argument is loaded with an assumption. In the case of ladders to the moon, we know the governing rules and the limits of possibility. But to extend the metaphor to AGI, we don’t understand our own intelligence well enough and we cannot say for sure that the chasm between a statistical model and causal reasoning is impervious. Like the expression Turtles all the way down, perhaps our intelligence is also made of statistical models stacked all the way down.
What do the critics say?
It is not as good as SOTA
To be correct, GPT-3 is not the best model out there. On most NLP tasks & benchmarks, other State-of-the-art (SOTA) algorithms perform better than GPT-3. But those criticisms are missing the point.
- Most of the SOTA algorithms are fine-tuned for specific tasks whereas GPT-3 is not. But GPT-3 has still learned to do these tasks by understanding (in a specific sense) the English language, somewhat similar to how humans learn language tasks. And this, not the benchmark performance, is the most talked-about aspect of GPT-3.
- SOTA also performs better than humans on many specific tasks like object recognition, mastering games like Chess and Go. But that doesn’t weigh against the ability of our general intelligence. General intelligence, in a sense, always has to underfit to have wider applicability.
One should also note that, in spite of being a general-purpose model, GPT-3 betters fine-tuned SOTA in some benchmarks (PhysicalQA, LAMBADA, Penn Tree Bank to name a few)
It is just an autocomplete
Another common criticism is that GPT-3 is just a sophisticated text prediction engine. It doesn’t understand what those words mean. But this is a hasty criticism based on an intuitive definition understanding. Our intuitions about intelligence, understanding, and meaning are not precise enough for such claims.
Let us say our brain is a sophisticated lookup dictionary populated by past experiences and culturally accumulated knowledge. Suppose a non-human entity possesses a similar dictionary but populated using a different process (by training on text corpus for example). Can it claim to have an understanding? This was the crux of the argument laid down by Searle in his Chinese room thought experiment.
Searle claims that looking up a dictionary doesn’t represent understanding, but not everyone agrees with that take. On a similar note, if we dismiss GPT-3’s output as a mere statistical calculation, there is no telling that our brain’s neuro-biological process is any different.
It has already seen the data it is predicting on
This is a more serious allegation than the ones above. Since GPT-3 was trained on a huge volume of data, there is a chance that it has already seen the inputs and it is simply recalling them from memory. For example, Yannic Kilcher in his video suspects that it can do arithmetic predictions because the model is likely to have seen the same data in the training dataset. OpenAI team claims to have done sufficient deduplication to remove the testing dataset from the training data. But given the volume of data, their deduplication is only optimistic.
But there is evidence that transformer models can indeed generate answers that it has not seen before. Karpathy trained a mini GPT model exclusively on synthetic data and it was already able to do 2 digit arithmetic. In this case, there is a clear separation between the training set and the validation set. So to conclude, the results we see from GPT-3 is not impossible and need not necessarily come out of a training data set corruption.
Conclusion
All these comparisons with AGI don’t mean we should haphazardly claim that GPT-3 is an AGI or that it definitively proves that AGI is possible. However, there are few interesting observations from the results of GPT-3:
- It shows that NLP models can be a shortcut to AGI as they have the ability to indirectly model the physical world.
- The performance of the GPT model continues to scale with the model size and hasn’t tapered off yet. So there is the promise that bigger models can be more intelligent.
- At higher model complexities, interesting behaviors seem to emerge, such as the ability to learn new tasks, perform non-linguistic tasks, etc.,
The year 2018 has been called the ImageNet moment for NLP and we can see why. The amount of progress made in NLP during the last couple of years is staggering and there is continued interest and investments in the domain. And mastering the NLP domain is closely linked with mastering General Intelligence.
There are many who believe that intelligence is somewhat innate to biological processes and cannot be reduced to mathematical models. There are others who believe that it is possible. In a way, this is just another incarnation of the nature vs nurture debate raging in the philosophical world for centuries. Except for this time, we are not relying on thought experiments. We get to do real experiments and see the answers in reality. Whichever side of the fence one sits on, the world waits with bated breath as the story unfolds.